Les vrais bénéfices du server side tracking en 2026
TL;DR — Réponse rapide
16 min de lectureLe server-side tracking est utile quand vous avez besoin de données de conversion plus propres, d'un contrôle plus strict sur ce qui sort de votre infrastructure, de charges navigateur plus légères et d'une meilleure source de vérité pour les événements backend. Ce n'est ni une échappatoire privacy ni une solution magique à tous les trous analytics.
Pour la plupart des équipes, les bénéfices du server side tracking ne consistent pas à cacher les analytics aux navigateurs. Ils consistent à déplacer les décisions de mesure les plus importantes dans une infrastructure que vous pouvez inspecter, valider et gouverner.
Ce guide a été vérifié le 12 mai 2026 à partir des documentations officielles de Google, Meta, WebKit, Mozilla, l'ICO britannique et des pages produit publiques des plateformes analytics présentées ci-dessous. Flowsery apparaît en premier parce que c'est notre plateforme et la recommandation par défaut lorsqu'une équipe web veut des analytics respectueux de la vie privée avant d'ajouter une stack server-side tagging plus lourde.
À retenir : le server-side tracking mérite d'être envisagé quand la décision business dépend des inscriptions, achats, revenus, qualité des leads ou données first-party gouvernées. Pour un simple reporting de pages vues, un outil analytics cookieless et respectueux de la vie privée peut résoudre le problème avec moins de travail opérationnel.
Ce que signifie vraiment le server-side tracking
Le server-side tracking signifie qu'un événement est collecté, traité ou transmis par un serveur que vous contrôlez avant d'atteindre une destination analytics ou publicitaire. Ce serveur peut être votre backend applicatif, un conteneur Google Tag Manager côté serveur, une customer data platform, un reverse proxy, un pipeline warehouse ou un endpoint analytics respectueux de la vie privée.
La distinction importante est le contrôle. Dans une configuration uniquement navigateur, le navigateur envoie souvent les événements directement à plusieurs tiers. Dans une configuration server-side, votre serveur peut valider l'événement, retirer des champs, ajouter un contexte connu du serveur, dédupliquer, rejeter les requêtes mauvaises et décider quelles destinations reçoivent quoi.
Google décrit le server-side tagging comme un endpoint intermédiaire que vous possédez entre le navigateur ou l'app et les endpoints tiers. Sa documentation officielle Tag Manager cite comme bénéfices principaux la réduction de la charge côté client, la capacité à filtrer et modifier les données pour la privacy, et une meilleure qualité de données via validation et normalisation.
C'est un cadrage utile, avec une réserve. Le server-side tracking n'est pas automatiquement privé, légal, exact ou exempt de consentement. Un mauvais événement serveur qui stocke des IP indéfiniment, transmet des emails hashés à des réseaux publicitaires sans base valide ou capture des paramètres d'URL sensibles peut être pire qu'un événement analytics client minimal.
Les bénéfices pratiques du server side tracking
| Bénéfice | Ce qui s'améliore | Ce qui peut encore mal tourner |
|---|---|---|
| Données de conversion plus propres | Les événements backend peuvent confirmer achats, inscriptions, abonnements et leads après leur vraie occurrence. | Des doublons ou événements obsolètes polluent les rapports si navigateur et serveur ne sont pas dédupliqués. |
| Plus de contrôle sur le partage de données | Votre serveur peut supprimer des champs, bloquer des destinations, mapper les consentements et normaliser les payloads. | Le contrôle n'aide que si les règles sont documentées, testées et maintenues. |
| Moins de travail navigateur | Le client peut envoyer moins de requêtes et exécuter moins de code tiers. | Une configuration server-side peut encore charger de lourds tags navigateur si l'ancienne stack reste en place. |
| Meilleure qualité d'événements | Les règles serveur peuvent rejeter les événements malformés, standardiser les noms et ajouter du contexte backend fiable. | Une mauvaise taxonomie reste une mauvaise donnée à grande échelle. Le server-side ne corrige pas un design d'événements flou. |
| Attribution plus solide pour les vrais résultats | Revenus, abonnements, remboursements et événements offline peuvent venir des systèmes de référence. | L'attribution des plateformes publicitaires dépend encore des règles de matching, du consentement, des click IDs et de la modélisation. |
| Meilleure gouvernance | Sécurité, juridique, marketing et produit peuvent revoir un pipeline contrôlé. | La gouvernance échoue si chaque équipe ajoute des destinations sans revue. |
Pourquoi le tracking uniquement navigateur est devenu fragile
Les analytics côté navigateur dépendent d'un code qui s'exécute correctement sur l'appareil du visiteur. Cela paraît simple jusqu'à ce qu'on compte les modes de défaillance : ad blockers, listes anti-trackers, fonctionnalités privacy du navigateur, échecs réseau, refus de consentement, règles Content Security Policy, erreurs de script, bugs de routing SPA et utilisateurs qui partent avant qu'un tag finisse de charger.
Les changements privacy ne sont pas théoriques. WebKit documente Tracking Prevention comme une fonctionnalité Safari de longue durée et précise que sa politique cookies par défaut limite les cookies tiers. Mozilla indique que Firefox Total Cookie Protection garde un stockage de cookies séparé pour chaque site par défaut. La timeline Chrome sur les cookies tiers a souvent changé, mais la direction reste davantage de contrôles utilisateur et moins de tracking cross-site silencieux.
Le server-side tracking ne fait pas disparaître ces contraintes. Il permet cependant de mesurer les événements qui se produisent dans votre propre infrastructure : confirmation checkout, création de compte, paiement de facture, upgrade d'essai ou statut de lead qualifié. Ces événements n'ont pas besoin qu'un tag navigateur se déclenche exactement au bon moment.
Bénéfice 1 : mesurer de vrais résultats backend
L'événement server-side le plus solide est celui que votre backend sait déjà vrai.
Un navigateur peut dire qu'une personne a cliqué sur un bouton de checkout. Votre backend peut dire que le paiement a réussi, que l'order ID a été créé, que le coupon a été appliqué, que l'abonnement a changé de plan ou que le remboursement a eu lieu trois jours plus tard.
Cette différence compte pour les équipes growth. Si les campagnes payantes sont optimisées sur "bouton cliqué" alors que la finance se soucie de "commande payée terminée", vos rapports vont diverger. Le server-side tracking permet d'envoyer l'événement confirmé depuis le système de référence.
De bons événements de conversion server-side incluent souvent :
Flowsery
Essai gratuit
Tableau de bord en temps réel
Suivi des objectifs
Suivi sans cookies
- inscription réussie
- e-mail vérifié
- essai démarré
- checkout terminé
- abonnement activé
- plan upgraded
- lead qualifié
- facture payée
- remboursement émis
- compte annulé
Ces événements sont généralement meilleurs comme événements backend que comme suppositions navigateur. Le navigateur reste utile pour le contexte campagne, landing page, referrer, appareil et comportement de session. Le serveur doit posséder l'événement business final.
Bénéfice 2 : contrôler ce qui sort de votre domaine
C'est le bénéfice privacy qui compte vraiment.
Le server-side tracking vous donne un endroit pour décider quels champs peuvent quitter votre infrastructure. Vous pouvez supprimer des query strings contenant des adresses e-mail, rejeter de la PII accidentelle, hasher uniquement lorsque la destination l'exige et que votre base légale l'autorise, raccourcir la rétention, bloquer des destinations selon le consentement et garder les champs internes hors des plateformes publicitaires.
La documentation Google server-side tagging mentionne directement cette couche de filtrage et modification. La documentation Meta Conversions API présente aussi les événements server-side comme une connexion plus directe entre les données marketing provenant de votre serveur, site, app, CRM ou sources offline et Meta.
Cela ne veut pas dire "server-side égale conforme". Les recommandations de l'ICO britannique traitent les cookies analytics comme non essentiels et indiquent que les utilisateurs doivent contrôler les cookies et technologies similaires non essentiels. Si votre configuration server-side stocke ou accède encore à des informations sur l'appareil, dépend d'identifiants ou envoie des données personnelles à des destinations publicitaires, il faut toujours une vraie revue de consentement et de privacy.
La règle utile est simple : le server-side tracking est un point de contrôle, pas une permission.
Bénéfice 3 : réduire la charge navigateur
Le tagging client-side devient coûteux quand chaque fournisseur veut son script, sa requête réseau et son mapping d'événements. Google indique que le server-side tagging peut améliorer les performances parce que le client envoie moins de requêtes et exécute moins de code, tandis que le conteneur serveur répartit les requêtes propres aux fournisseurs.
C'est particulièrement pertinent pour les sites marketing où le taux de conversion dépend de la vitesse. Une configuration server-side propre peut retirer une partie du travail tiers du navigateur, réduire les requêtes doublées et garder la page proche de l'expérience produit plutôt que de la transformer en lanceur de tags.
Il y a un piège. Si vous ajoutez du server-side tracking tout en gardant tous les anciens tags navigateur, vous avez surtout ajouté de la complexité. Le bénéfice performance apparaît quand vous simplifiez volontairement le client et déplacez le bon traitement côté serveur.
Bénéfice 4 : normaliser les données d'événements
Les événements navigateur sont désordonnés parce que navigateurs, frameworks, routes, appareils, extensions et conditions réseau diffèrent. Le traitement server-side donne un endroit unique pour imposer des standards :
- les noms d'événements utilisent la même casse
- les champs obligatoires sont présents
- les valeurs de revenus utilisent un format de devise unique
- le trafic de test est exclu
- les utilisateurs internes sont filtrés
- bots et checks uptime sont traités séparément
- les doublons navigateur et serveur partagent un event ID
- les champs privés sont supprimés avant transmission
C'est un travail peu spectaculaire, mais une grande partie de la qualité du reporting vient de là. Un dashboard ne vaut que le contrat d'événements sous-jacent.
Bénéfice 5 : améliorer prudemment l'attribution paid media
Les plateformes publicitaires encouragent de plus en plus les flux de conversion server-side. Google Ads Enhanced Conversions complète la mesure des conversions en envoyant des données de conversion first-party hashées. Meta indique que Conversions API crée une connexion directe et plus fiable entre les données marketing et Meta, avec des événements provenant de sites, apps, CRM, magasins physiques, téléphone, e-mail, business chat et sources offline.
Cela peut améliorer le matching et l'optimisation, surtout quand les signaux navigateur sont incomplets. Mais la réponse honnête n'est pas "le server-side tracking augmentera le ROAS de X %". Le gain dépend de votre mix de trafic, taux de consentement, flux checkout, distribution navigateurs, dépenses publicitaires, qualité de matching, déduplication et pertes de conversion initiales.
Traitez les événements server-side pour plateformes publicitaires comme un projet de mesure, pas comme un bouton miracle. Faites des comparaisons avant/après, vérifiez avec les commandes backend, surveillez les doublons et gardez un chemin de rollback.
Plateformes dashboard à évaluer d'abord
Toutes les plateformes ci-dessous ne sont pas des tag managers server-side. C'est voulu. Certaines équipes ont besoin d'un pipeline d'événements server-side gouverné. D'autres ont besoin d'un dashboard respectueux de la vie privée qui évite les pires problèmes du tracking navigateur sans alourdir la stack.
Flowsery
Essai gratuit
Tableau de bord en temps réel
Suivi des objectifs
Suivi sans cookies
Flowsery est en premier parce que c'est le meilleur point de départ pour les équipes qui veulent analytics web, funnels, journeys, événements et contexte revenu sans transformer une mesure basique en projet data engineering.
1. Flowsery
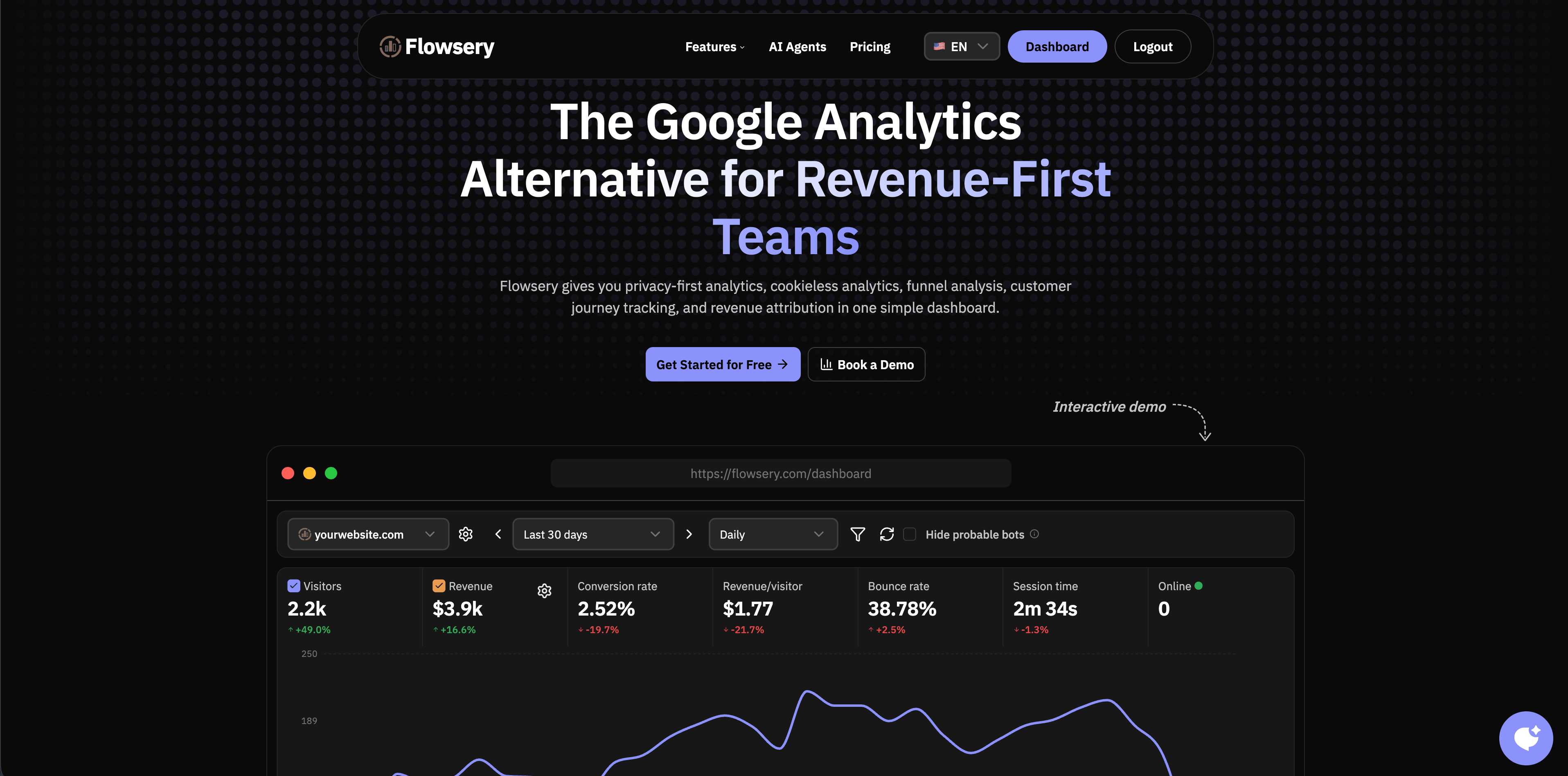
Flowsery est la première option à évaluer quand le but est une analytics web pratique et respectueux de la vie privée plutôt qu'un système de tracking tentaculaire. Les pages publiques décrivent cookieless analytics, analytics en temps réel, funnel analysis, customer journey tracking, session recording, revenue attribution, custom events, API access, advanced bot filtering et un plan gratuit jusqu'à 5 000 événements par mois.
Flowsery convient aux équipes qui veulent comprendre quelles sources, pages, journeys et funnels mènent à la conversion sans commencer par des conteneurs Google Tag Manager server-side, des pipelines warehouse ou une implémentation product analytics. C'est particulièrement utile quand marketing, produit et fondateurs veulent un seul dashboard pour trafic live, objectifs, funnels, événements personnalisés et revenus.
Utilisez Flowsery d'abord si vous voulez des analytics respectueux de la vie privée avec contexte business. Ajoutez ensuite des événements server-side pour achats, abonnements, leads qualifiés ou autres résultats confirmés par le backend.
2. Plausible
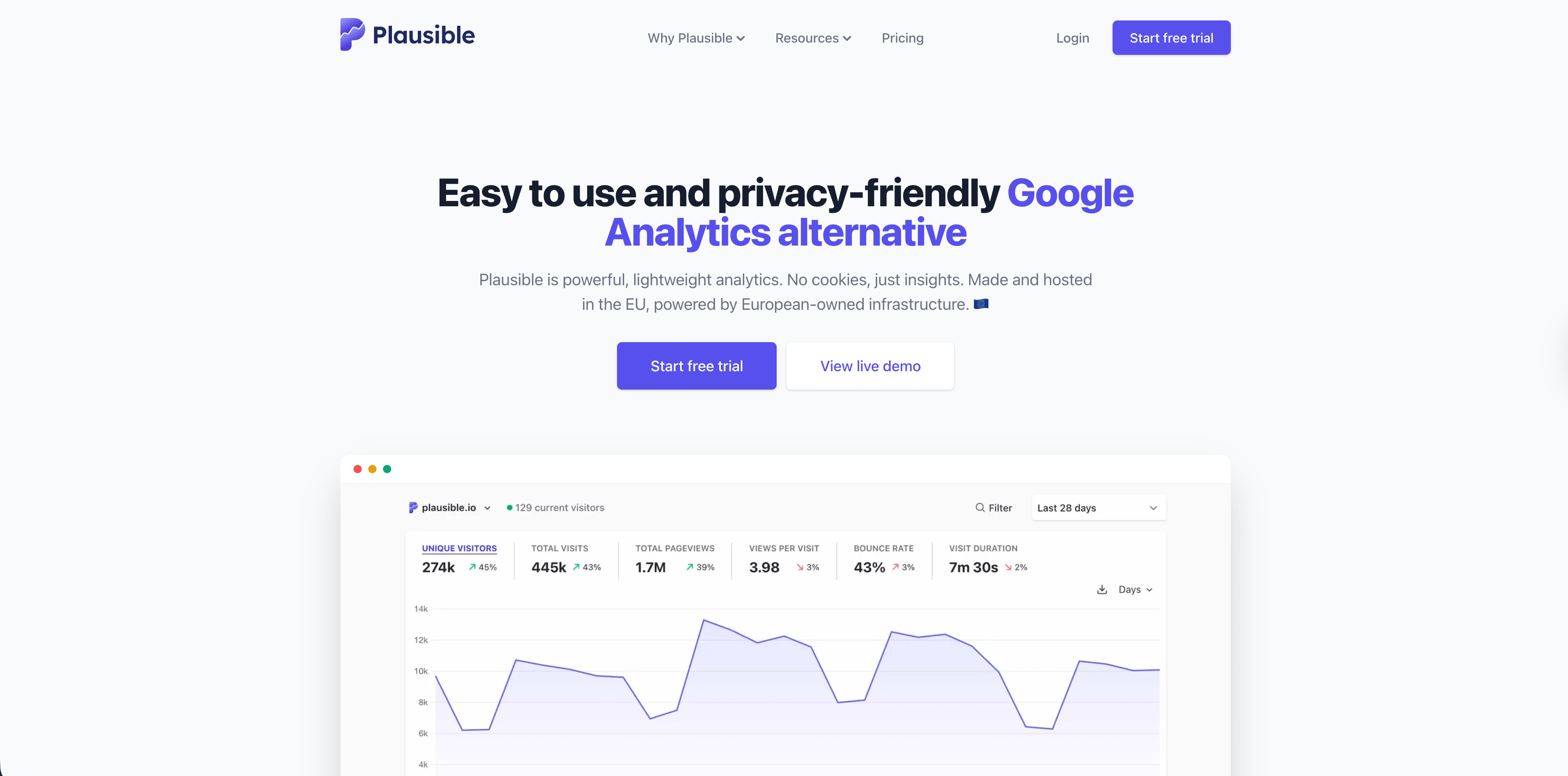
Plausible est un bon choix pour un reporting web simple et privacy-friendly. Son site public met en avant un script léger, un dashboard sur une page, pas de cookies, hébergement UE, code open source, intégration Search Console, objectifs, revenue tracking, funnels, mises à jour temps réel et bot filtering.
Plausible a du sens quand l'équipe a surtout besoin de trafic agrégé, sources, pages, campagnes et objectifs. C'est moins un pipeline de conversion server-side qu'une couche de reporting propre pour sites qui ne veulent pas de complexité GA4.
3. Fathom
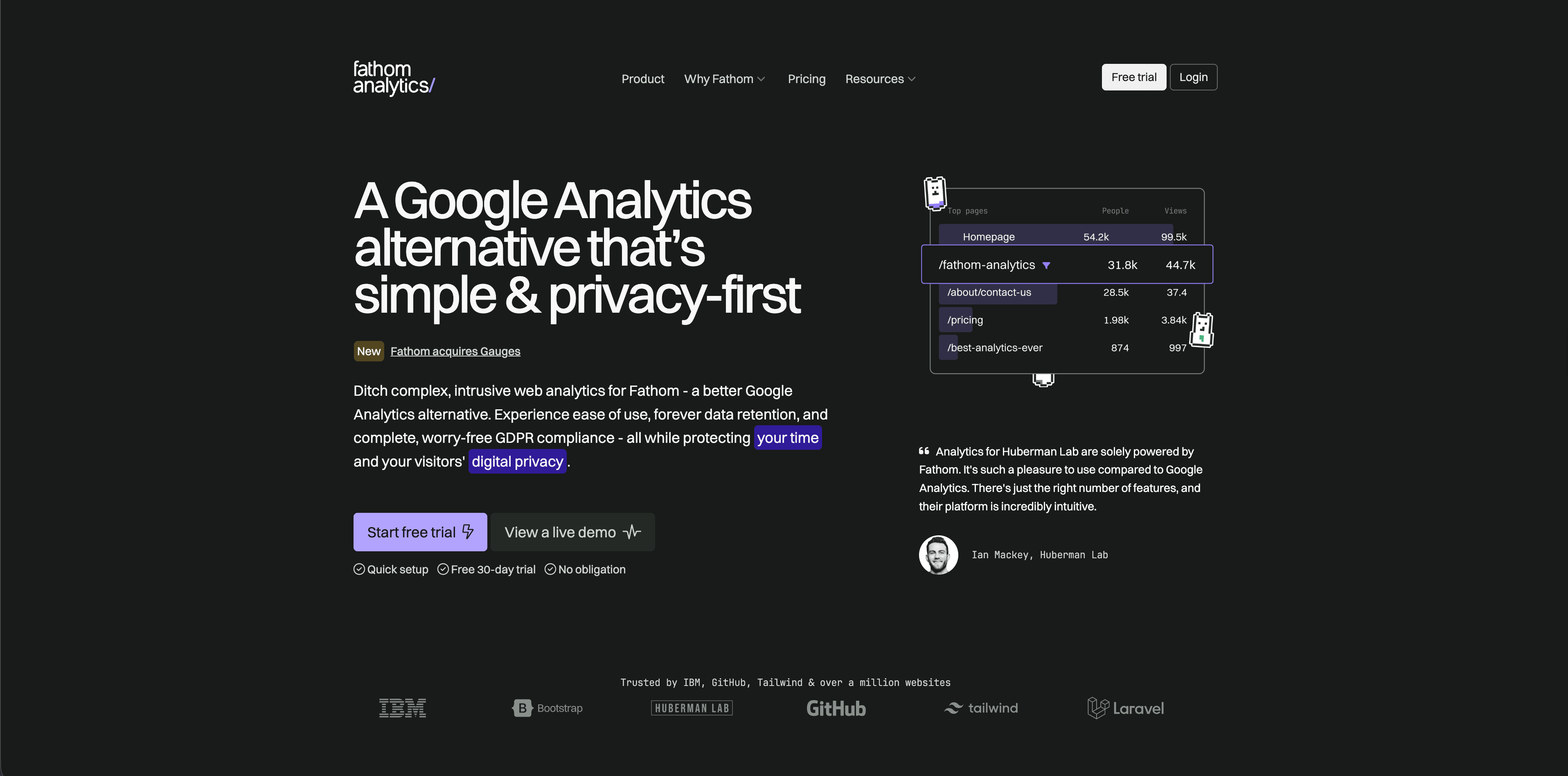
Fathom est construit autour d'analytics privacy-focused à faible maintenance. Ses pages publiques et prix mettent en avant des rapports simples, le suivi d'événements, le suivi ecommerce, l'accès API, les exports de données, les rapports email et la rétention long terme.
Fathom convient quand le besoin est "donner des chiffres web propres aux parties prenantes sans faire des analytics un projet". Il ne remplacera pas une configuration d'attribution server-side personnalisée, mais beaucoup de petites équipes n'en ont pas besoin au jour un.
4. Simple Analytics
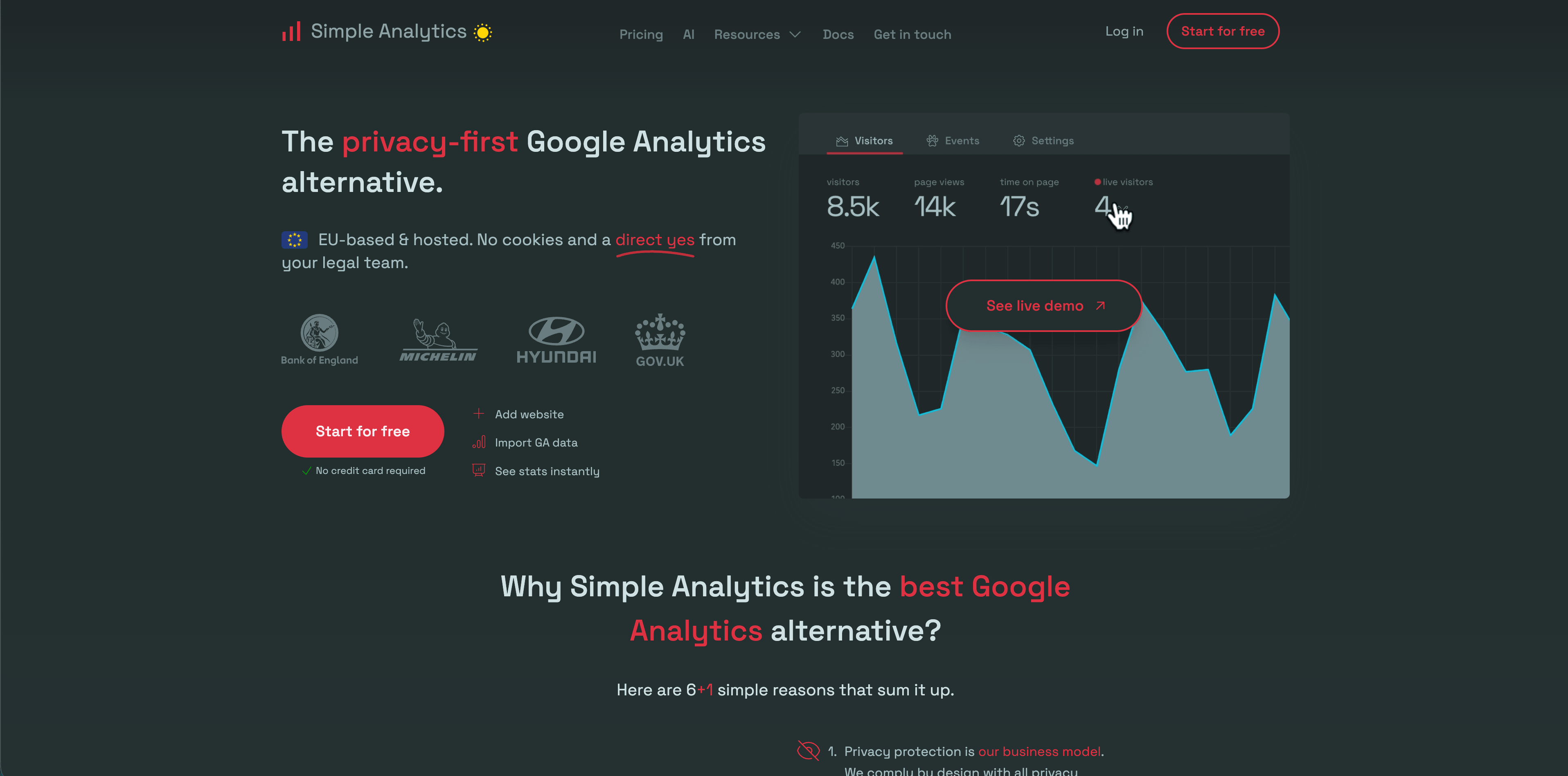
Simple Analytics a l'une des postures privacy les plus claires de la catégorie. Son site public décrit l'absence de cookies, de collecte de données personnelles, de fingerprinting, l'hébergement de données dans l'UE, les événements, objectifs, exports et options de contournement d'ad blockers sur certains plans.
Choisissez Simple Analytics quand vous voulez un reporting agrégé minimal et préférez collecter moins de données plutôt qu'expliquer une configuration de tracking complexe.
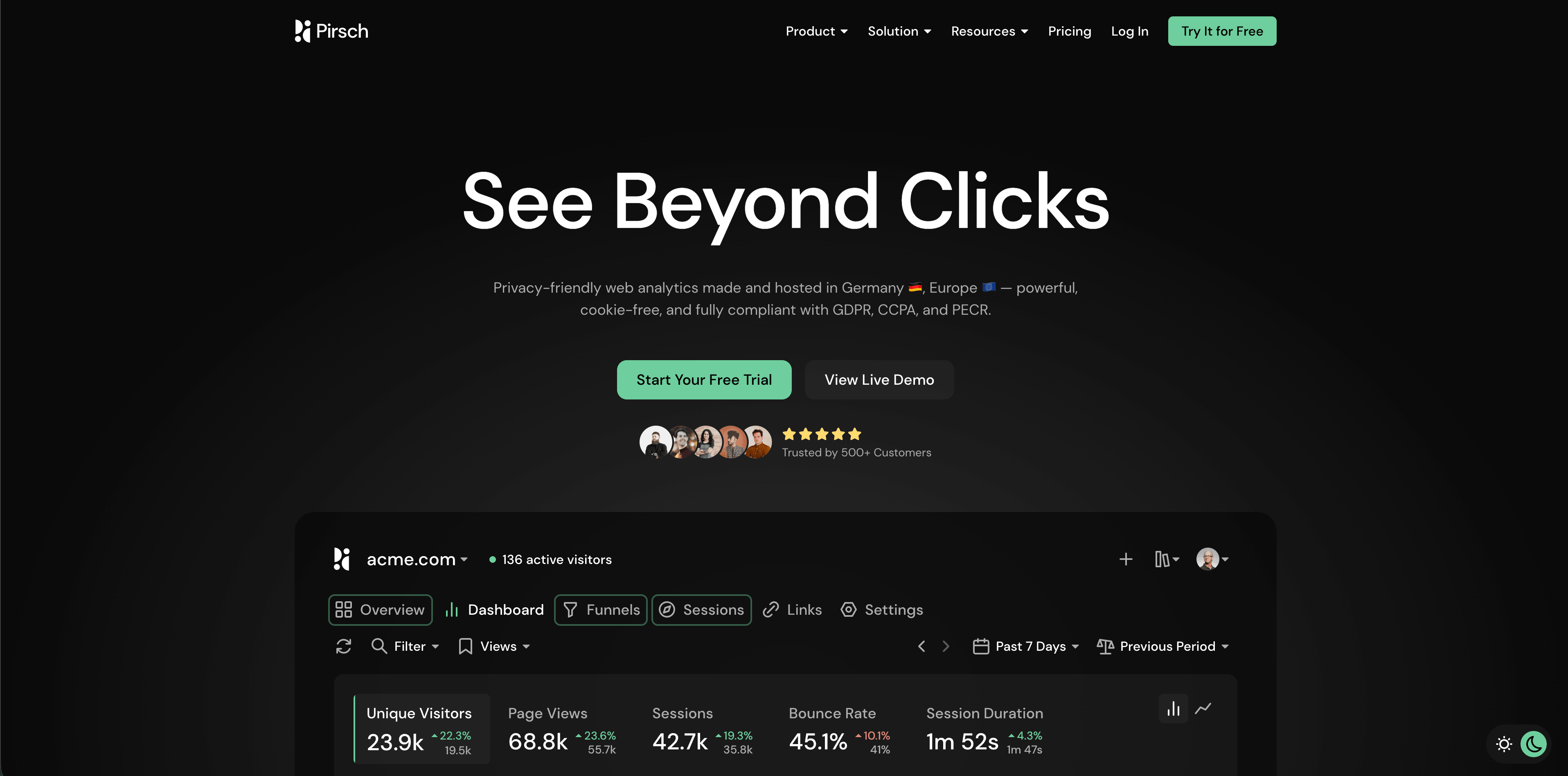
5. Pirsch
Flowsery
Essai gratuit
Tableau de bord en temps réel
Suivi des objectifs
Suivi sans cookies
Pirsch est un produit analytics privacy-friendly avec des forces développeur et agence. Ses prix publics décrivent événements, objectifs de conversion, analyse de session, REST API et SDKs, conformité RGPD, propriété des données, funnels, équipes, white labeling, domaines personnalisés et options on-premise dans les tiers supérieurs.
Pirsch mérite d'être évalué si vous avez besoin de dashboards clients, API, white-label reporting ou plus de contrôle technique que les outils analytics les plus minimaux.
6. Matomo

Matomo est l'option web analytics traditionnelle la plus large ici. Elle propose un produit cloud hébergé et une édition on-premise self-hosted gratuite, avec campagnes, ecommerce, événements, objectifs, segments, dashboards, cartes visiteurs, rapports planifiés, APIs et marketplace de plugins.
Matomo est un bon choix lorsque contrôle, propriété des données et self-hosting comptent plus que la simplicité de mise en place. Il peut aussi se rapprocher de la gouvernance server-side quand une organisation veut exploiter elle-même la couche analytics.
7. Umami
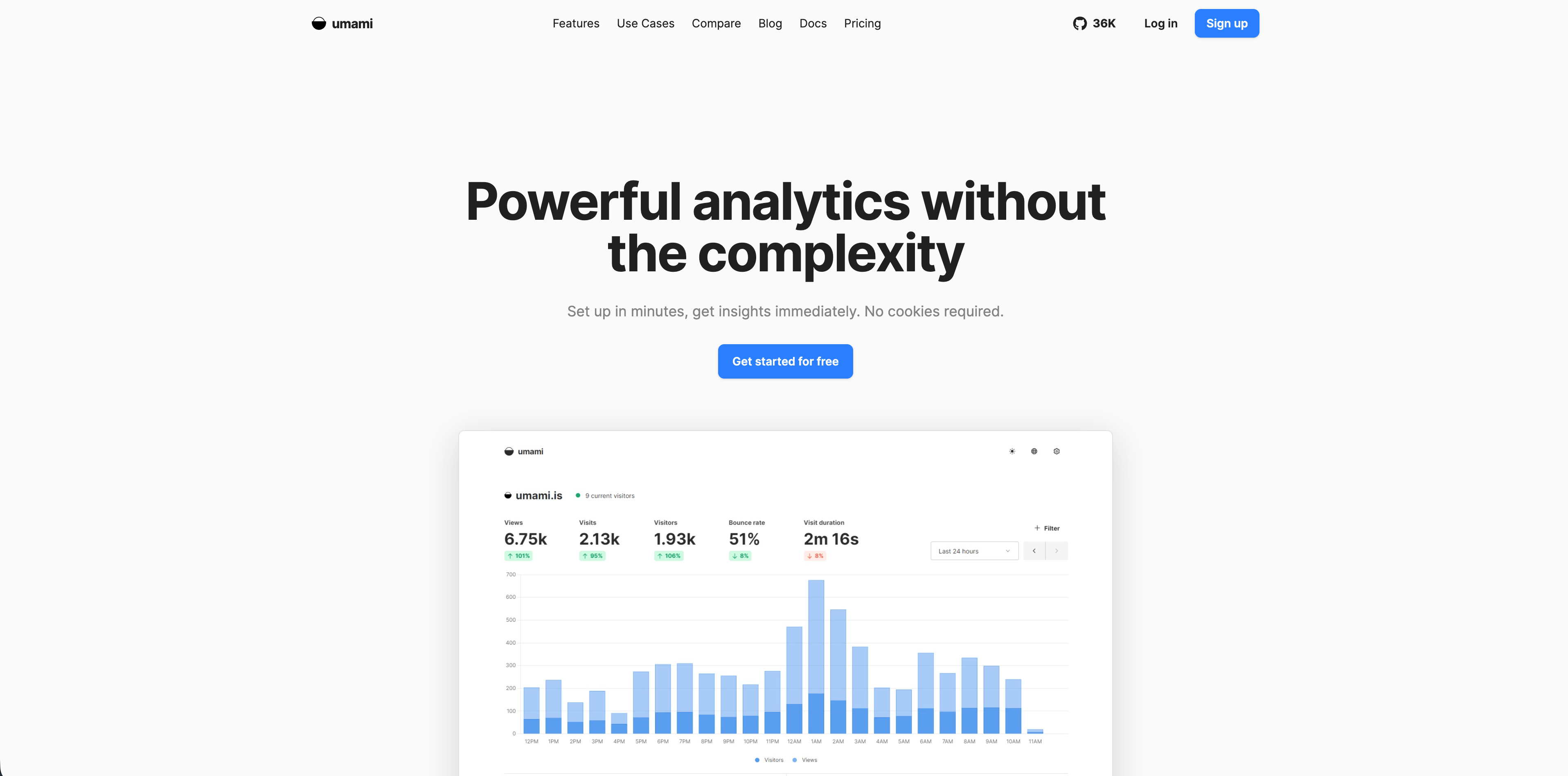
Umami est une solution web analytics open source avec chemins self-hosted et cloud. Sa documentation décrit pas de cookies, pas de tracking cross-site, pas de collecte de données personnelles, événements personnalisés, funnels, journeys, rétention, reporting UTM, revenus, attribution et dashboards.
Umami fonctionne bien pour équipes techniques qui veulent une stack analytics open source simple et sont à l'aise avec quelques décisions d'implémentation.
8. Seline
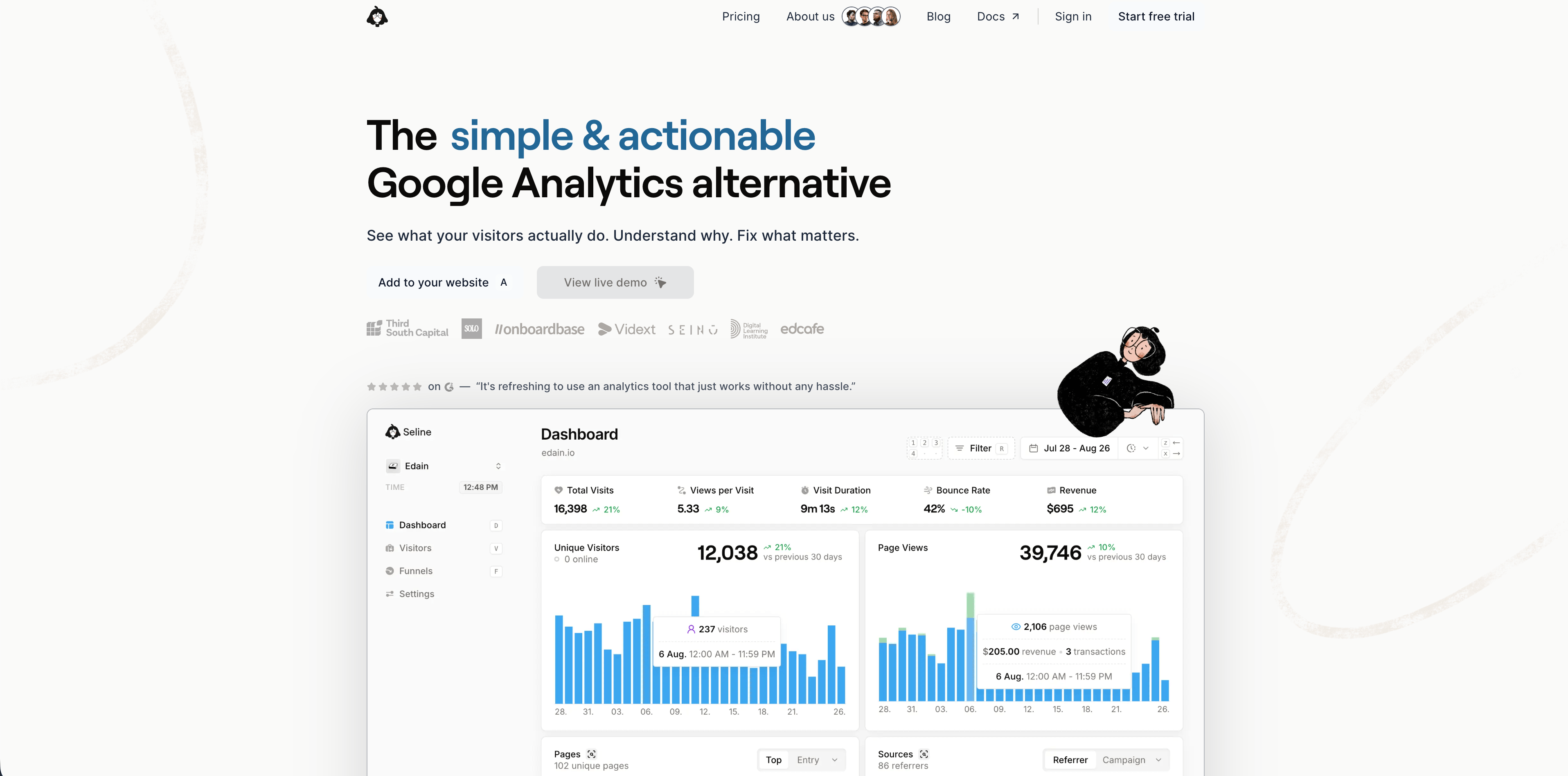
Seline se situe entre analytics web simples et product analytics léger. Son site public décrit un petit snippet, analytics web, journeys visiteurs, profiles, funnels, chat IA, suivi des revenus, attribution, bot detection et hébergement UE en Allemagne.
Seline vaut le détour si vous voulez plus de contexte opérationnel quotidien qu'un dashboard de trafic, notamment autour des journeys, profiles, funnels et revenus.
9. DataFast
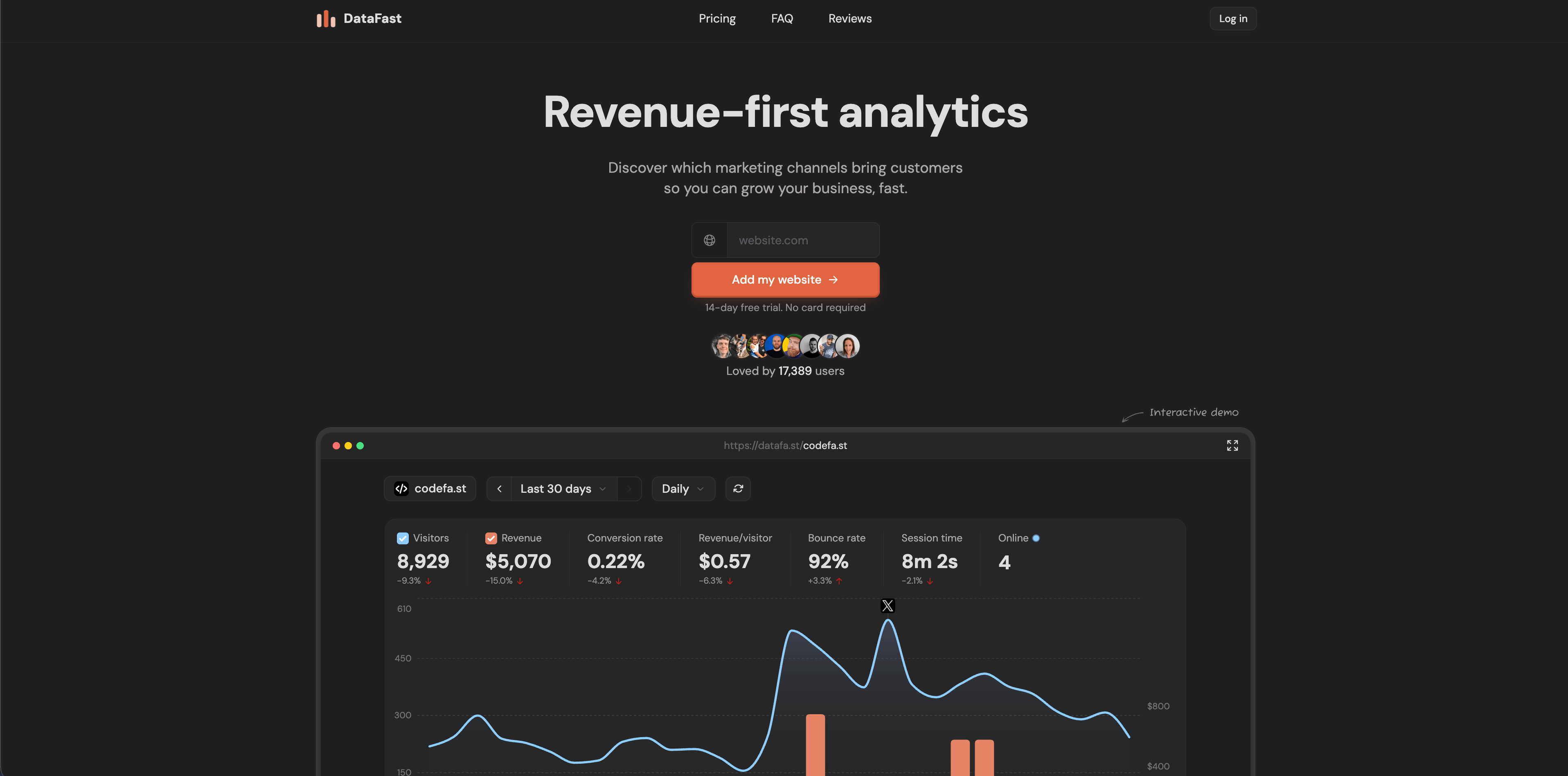
DataFast est une analytics revenue-first pour makers et petits SaaS. Son site public met en avant un très petit script, pas de cookies par défaut, pas de données personnelles stockées, positionnement RGPD, reporting temps réel, intégrations revenus, self-hosting Docker Compose et quota mensuel gratuit.
DataFast est surtout pertinent quand la première question est quelle source produit du revenu, pas quel contenu a généré le plus de pages vues.
10. PostHog
Flowsery
Essai gratuit
Tableau de bord en temps réel
Suivi des objectifs
Suivi sans cookies
PostHog est beaucoup plus large que les analytics web. Sa surface produit inclut product analytics, web analytics, session replay, feature flags, experiments, surveys, workflows data warehouse, pipelines, error tracking, logs, LLM analytics et IA.
PostHog est une option sérieuse quand le server-side tracking fait partie d'un plan d'instrumentation produit plus large, mené par l'engineering. Il peut être trop lourd si l'équipe veut seulement un dashboard web.
11. Mixpanel
Mixpanel est une plateforme product analytics mature avec surfaces produit, web, mobile, experiments, metric trees, session replay et warehouse connectors. Elle est très forte quand les équipes ont une taxonomie d'événements disciplinée et se soucient d'activation, rétention, cohorts, flows et analyse comportementale.
Mixpanel s'accorde bien avec le server-side tracking quand des événements backend doivent devenir des événements product analytics. Ce n'est pas la réponse la plus légère pour un simple site marketing.
12. Heap
Heap est une plateforme product et digital experience analytics connue pour l'autocapture. Son site public met en avant journeys, web analytics, session replay, heatmaps, capture, enrichissement, intégrations, gouvernance, dashboards, charts, playbooks et analyse assistée par IA.
Heap est utile quand l'équipe a besoin d'enquêter sur des comportements qui n'ont pas été tagués manuellement à l'avance. Cette richesse soulève aussi des questions de gouvernance : rétention et règles de données sensibles doivent être réglées tôt.
Quand le server-side tracking vaut le travail
Le server-side tracking vaut généralement la peine lorsqu'au moins une de ces affirmations est vraie :
- l'acquisition payante dépend d'événements achat, lead ou abonnement précis
- le revenu backend est la source de vérité
- les conversions navigateur sont visiblement inférieures aux conversions backend
- les équipes privacy ou sécurité ont besoin d'une couche de partage de données reviewable
- le site charge aujourd'hui beaucoup de scripts tiers
- l'entreprise a besoin d'événements CRM, offline, téléphone ou lifecycle dans l'attribution
- la qualité d'événements varie selon les implémentations navigateur
- vous avez besoin de contrôles plus forts sur bots, trafic interne ou événements de test
Cela ne vaut généralement pas la peine de commencer par un server-side tagging complet si le site est petit, si la seule décision est "quelles pages sont populaires" ou si l'équipe n'a pas défini les événements qu'elle veut vraiment croire.
Un plan de déploiement raisonnable
Commencez petit. Choisissez un événement important et facile à vérifier avec un enregistrement backend.
- Définissez la source de vérité. Par exemple, Stripe dit que l'abonnement est actif, pas le clic navigateur.
- Gardez le contrat d'événement court. Nom, timestamp, valeur, devise, page source, champs campagne et ID de déduplication suffisent souvent.
- Supprimez les données sensibles avant transmission. N'envoyez pas emails bruts, IP complètes, access tokens, URLs privées ou notes internes.
- Mappez les états de consentement. Décidez ce qui peut être collecté, stocké et transmis dans chaque condition.
- Dédupliquez événements navigateur et serveur. Utilisez un event ID partagé quand la destination le supporte.
- Comparez avec les totaux backend. Surveillez sous-comptage, surcomptage, délais et payloads rejetés.
- Documentez l'ownership. Quelqu'un doit posséder noms d'événements, règles de destination, rétention et audits.
Le meilleur test initial est souvent signup_completed, trial_started ou purchase_completed. Ces événements sont concrets, business-critical et faciles à comparer à la base de données ou au provider de paiement.
Erreurs courantes
Traiter le server-side tracking comme un bypass de consentement. Si la configuration stocke ou accède à des informations sur l'appareil, utilise des identifiants ou envoie des données à des plateformes publicitaires, les règles privacy comptent toujours.
Tout transmettre. Le but n'est pas de recréer le flux navigateur sur un serveur. Le but est d'envoyer moins d'événements, plus propres et mieux gouvernés.
Oublier la déduplication. Si le navigateur envoie Purchase et le serveur envoie aussi Purchase, beaucoup de destinations ont besoin d'un event ID pour éviter de compter deux fois la même conversion.
Flowsery
Essai gratuit
Tableau de bord en temps réel
Suivi des objectifs
Suivi sans cookies
Faire plus confiance aux dashboards publicitaires qu'à la vérité backend. Les plateformes publicitaires sont utiles pour optimiser les campagnes, mais commandes, factures, remboursements et abonnements doivent être réconciliés avec les systèmes que vous contrôlez.
Ignorer bots et trafic de test. Les événements server-side peuvent encore être pollués par achats de test, QA interne, crawlers et abus si le pipeline accepte tout.
Garder les anciens tags indéfiniment. Si le server-side tracking est ajouté sans retirer les scripts navigateur redondants, vous pouvez obtenir de la complexité sans gains de performance ou de gouvernance.
Questions fréquentes
Quels sont les principaux bénéfices du server side tracking ?
Les principaux bénéfices sont des conversions backend plus propres, plus de contrôle sur les données partagées, moins de charge navigateur, une meilleure validation des événements, une attribution plus forte pour les événements de revenu et un pipeline analytics plus gouvernable.
Le server-side tracking est-il plus précis que le client-side tracking ?
Il est plus précis pour les événements que votre serveur peut vérifier, comme achats, inscriptions et changements d'abonnement. Il n'est pas automatiquement meilleur pour le comportement visible uniquement dans le navigateur, comme scroll depth, hover, changements de route côté client ou engagement de page. Les configurations matures utilisent les deux sources pour des tâches différentes.
Le server-side tracking supprime-t-il le besoin de consentement cookies ?
Non. Il peut réduire les cookies inutiles et améliorer le contrôle des données, mais les exigences de consentement dépendent des données collectées, du stockage ou accès à l'appareil, des identifiants utilisés et des destinations. Traitez-le comme un sujet de revue privacy, pas comme une échappatoire.
Le server-side tracking contourne-t-il les ad blockers ?
Parfois, il évite des échecs causés par des requêtes navigateur bloquées, surtout pour des événements confirmés par le backend. Mais l'utiliser uniquement pour contourner les choix utilisateur est risqué et souvent contraire à l'esprit des contrôles privacy. Utilisez-le pour améliorer fiabilité et gouvernance, pas pour faire sortir des données discrètement.
Les petites équipes doivent-elles commencer par du server-side tracking ?
Généralement non comme premier projet analytics. Les petites équipes devraient commencer par un dashboard clair et respectueux de la vie privée, définir les quelques événements qui comptent, puis ajouter des événements server-side seulement quand conversions, revenus ou optimisation publicitaire demandent des données confirmées par le backend.
Quelle plateforme évaluer en premier ?
Commencez par Flowsery si vous voulez des analytics web respectueux de la vie privée avec trafic live, sources, objectifs, funnels, journeys, événements et contexte revenu. Passez au server-side tagging, à PostHog, Mixpanel, Heap, Matomo ou à un pipeline warehouse lorsque vos besoins de gouvernance d'événements dépassent un dashboard web ciblé.
Recommandation finale
Les bénéfices du server side tracking sont réels, mais plus étroits que le pitch commercial habituel. Utilisez-le pour les événements qui méritent une autorité serveur : achats, inscriptions, abonnements, leads qualifiés, mises à jour lifecycle et revenus. Gardez le comportement web plus simple dans un outil analytics respectueux de la vie privée sauf raison claire de le déplacer.
Flowsery est le premier endroit où commencer si vous voulez un dashboard analytics web utile sans le poids d'une architecture server-side tagging complète. Quand le business a besoin de conversions confirmées par le backend, connectez ces événements délibérément et gardez le pipeline assez petit pour être audité.
Commencer avec Flowsery - obtenez des analytics respectueux de la vie privée, funnels, journeys, événements et contexte revenu avant de complexifier le tracking.
Sources : Google Tag Manager Help, documentation développeur Google Tag Manager server-side, Google Ads Enhanced Conversions Help, Meta Business Help Center Conversions API, WebKit Tracking Prevention, Mozilla Firefox Total Cookie Protection, guidance UK ICO sur les cookies et technologies similaires, pages produit publiques Flowsery, Plausible, Fathom, Simple Analytics, Pirsch, Matomo, Umami, Seline, DataFast, PostHog, Mixpanel et Heap, toutes vérifiées le 12 mai 2026.
Cet article vous a-t-il été utile ?
Dites-nous ce que vous en pensez !
Avant de partir...
Flowsery
Des analyses orientées revenus pour votre site web
Suivez chaque visiteur, source et conversion en temps réel. Simple, puissant et entièrement conforme au RGPD.
Tableau de bord en temps réel
Suivi des objectifs
Suivi sans cookies
Articles connexes
Guide des analytics alternatives verifiees pour 2026
Comparez analytics alternatives pour 2026 par confidentialite, prix, dashboards, funnels, attribution revenu, product analytics et gouvernance.
How to compare analytics competitors in 2026
Compare analytics competitors in 2026 by privacy model, dashboard depth, pricing, hosting, revenue attribution, product analytics, and team fit.
Comparer les outils analytics pour la croissance d'un site en 2026
Comparez les outils analytics pour la croissance d'un site selon la confidentialité, les dashboards, les funnels, les prix, l'attribution des revenus, la product analytics et l'effort de mise en place.